「差那么一点,总是差那么一点……」
经过了两天的奋战,辗转了三次方案,自己写了好几个脚本,终于完成了文件去重这艰难的任务。
将我的阿里云盘文件总量从 3.2T 降低到 2T,删掉了以十万计的重复文件们。虽然离我的永久容量还差那么一点点,但已不远矣。
下面这张图是我的最终方案的结果记录。经过了阿里云盘自带的 6k 组去重与小白羊客户端 >10M 的 8k 组去重后,我在 AliPCS-Py 的基础上拓展了去重功能,终于干碎了这剩下的 7w+ 组重复文件。
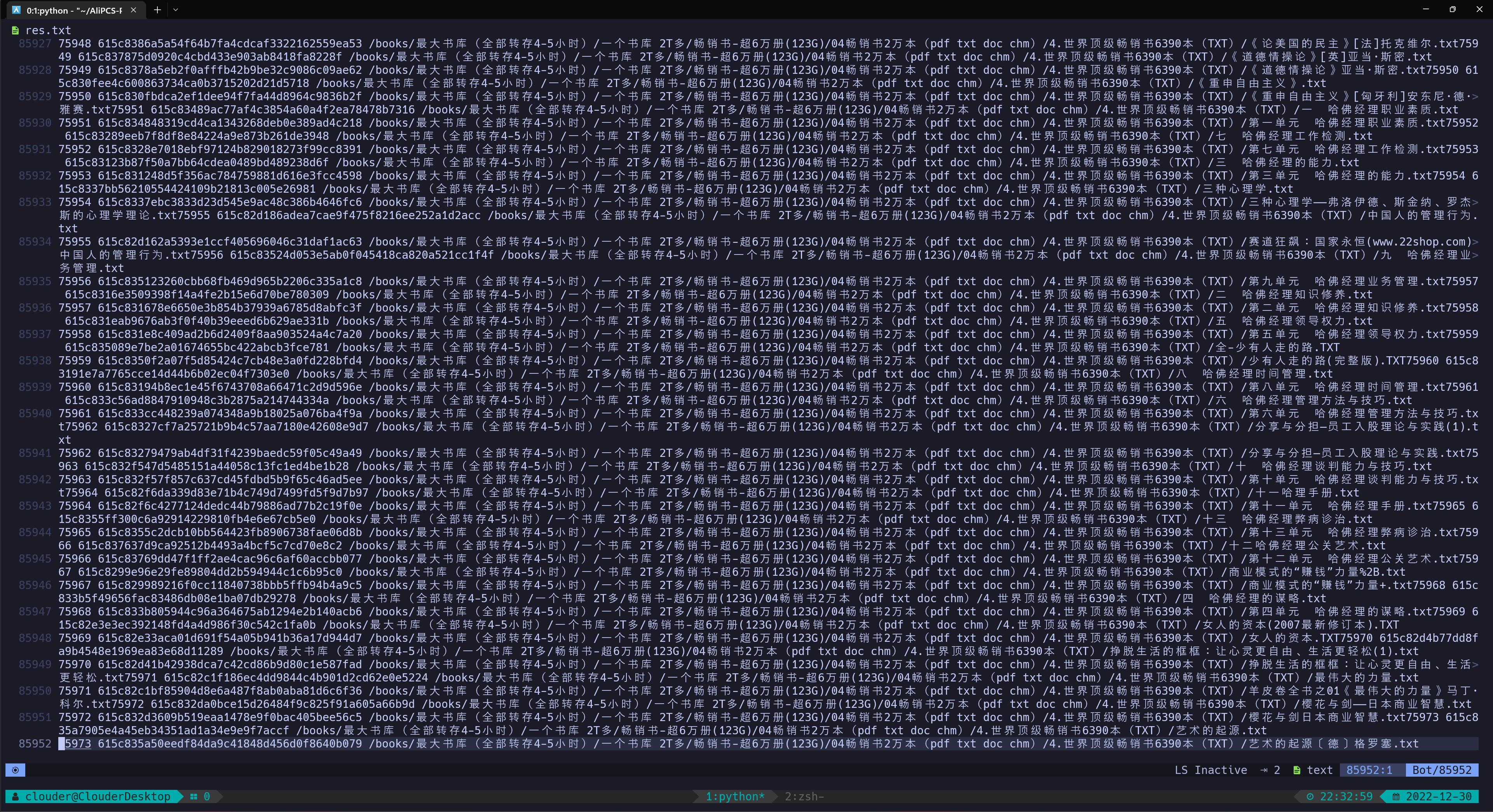
保存一时爽,去重火葬场啊!
经典时刻
万 无 一 失

很好!模拟测试 dry-run 非常顺利!进入生产环境实装!
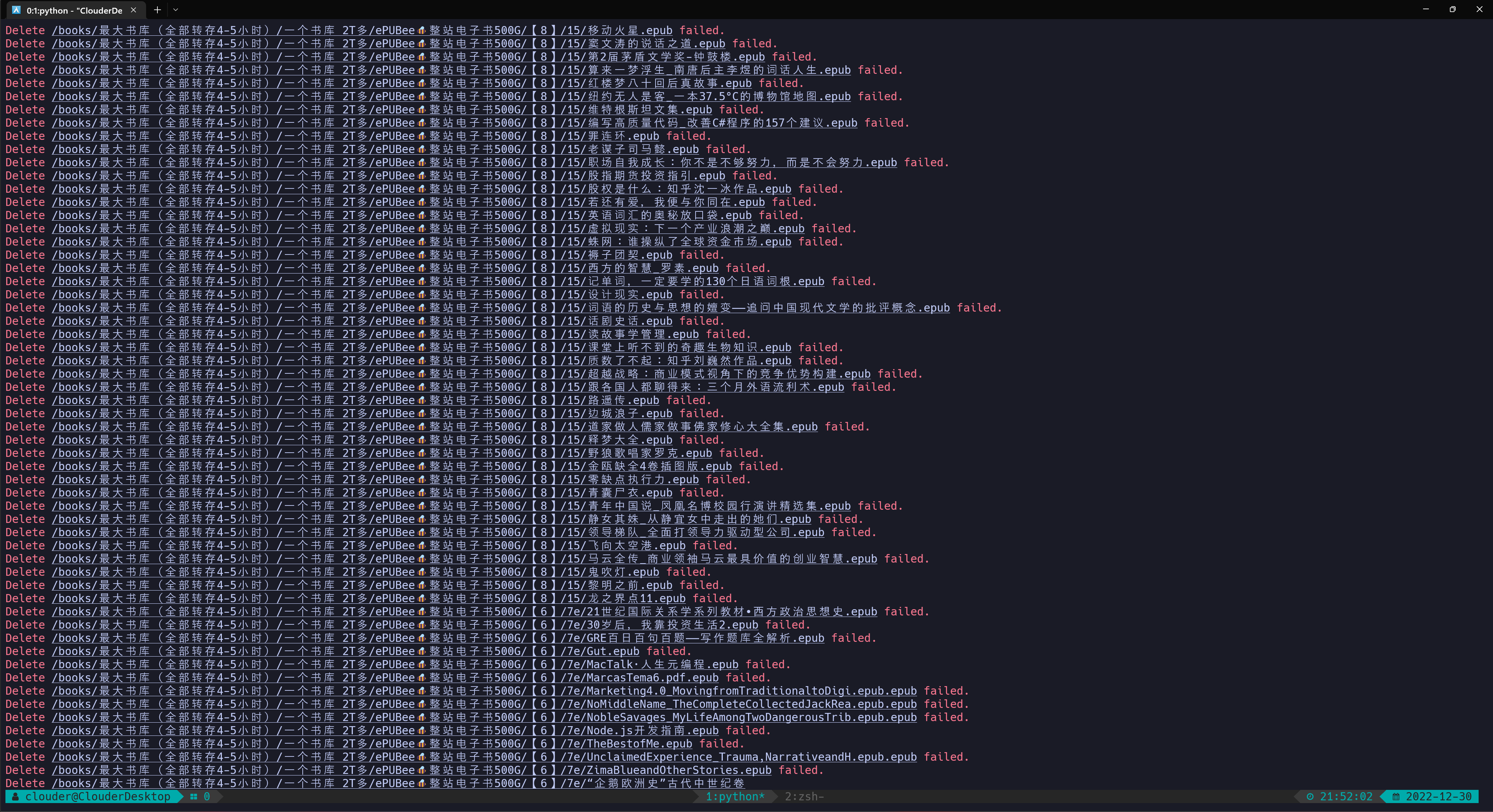

一 fail 到 底

奇了怪了,跑了这么久都不报错,是不是我的日志被吞了?总感觉心里不踏实,就像是不戴口罩出门溜了几圈后三天都还没阳的莫名其妙感。
于是——

一 fail 到 底。

秃头间,8w 文件灰飞烟灭~
二度删除
相信你已经知道我想要说什么了(
PS:用阿里云盘小白羊客户端删回收站速度还可以,每次删 100 个。
记录
Approach One 官方去重
为了使用这个去重功能,我还特地破费 8 元开了一个连续包月,然后今天取消了(
首先:这个重复文件清理扫描是不全的。我在最开始就尝试这个途径,扫出来 6k 组文件左右,连真实数量的一成都不到(
然后:这里虽然有智能筛选功能,但是!!智能筛选只对当前列表中的文件有效。而这个列表,像你想象的一样,是一个无限滚动列表,每次加载 20 组左右吧。
也就是说:你只要一直往下滚滚滚滚滚滚滚滚滚滚滚滚滚滚滚滚滚滚滚滚滚滚滚滚滚滚滚滚滚滚滚滚滚滚滚滚滚滚滚滚滚滚滚滚滚滚滚滚滚滚滚滚滚滚滚滚滚滚滚滚滚滚滚滚滚滚滚滚滚滚滚滚滚滚滚滚滚滚滚滚滚滚滚滚滚滚滚滚滚滚滚滚滚滚滚滚滚滚滚滚滚滚滚滚然后点智能筛选然后删除就可以啦!

于是愚昧无知的我只能用微软的 Power Automate 尝试自动化一下这个过程。
其实我最开始是想用 Chrome Dev Tools 里的那个 Recorder 的,但定位元素似乎有问题,所以就用 Power Automate 了。
这个时候又遇到了一个坑,微软的 Power Automate 如果在 msstore 安装则无法连接上浏览器拓展,而且经过我的实验,Chrome 拓展死活连不上,最后上了 Firefox. 为了用上它的浏览器拓展我连装两个浏览器,真是不容易啊。
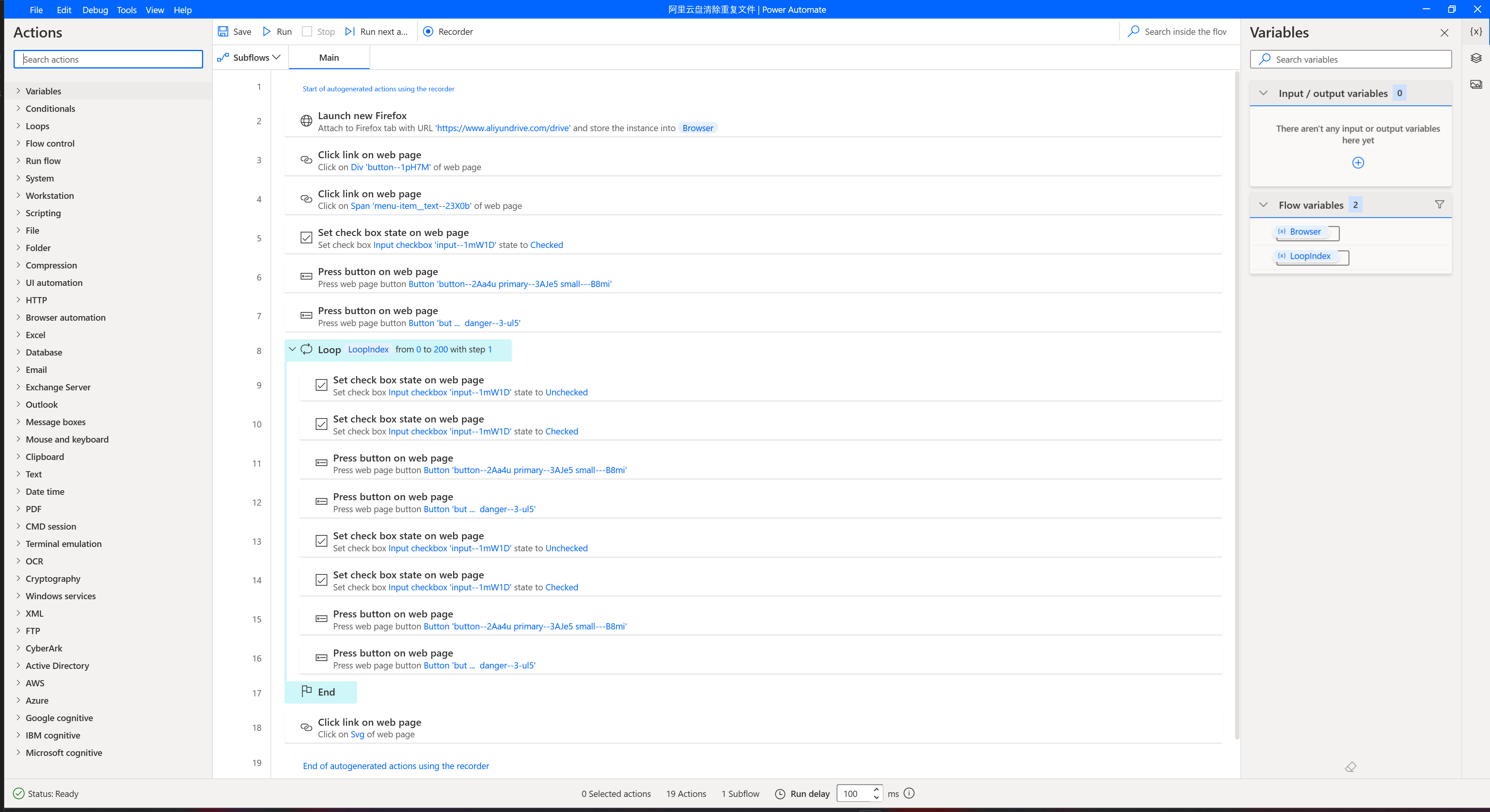
然后在 Power Automate 里面写好这个 Workflow,跑起来就可以啦。这玩意有一个好处:可以在后台运行,不用抢占前台鼠标。
于是磕磕绊绊但不算太磕磕绊绊地完成了官方去重。
Approach Two 小白羊去重
怎么说呢,真是充满了痛苦的一段尝试。
官方去重后,我发现还是有重复文件残留。于是我想起来,我曾经试图用阿里云盘小白羊客户端去重,不过当时还没开发出这个功能,但有这个 issue 了。
这次小白羊倒是确确实实有扫描重复文件功能了,但是——
这次不是无限列表了,很好,但是——没有批量选择功能。
想去重?一个个点吧……
深感蛋疼的我这次写了一个 Quicker 动作来帮我点击。其实 Power Automate 我也不太熟。
然后掉了一大堆莫名其妙的坑,什么识图偏移、双屏坐标漂移之类的各种问题,总之就是其实 Quicker 这方面的操作我也不太熟。
不过到了最后,我还是把这个玩意糊出来了。虽然我也不知道为什么这样能行,whatever, it works,甚至比我想象的还要更具鲁棒性……
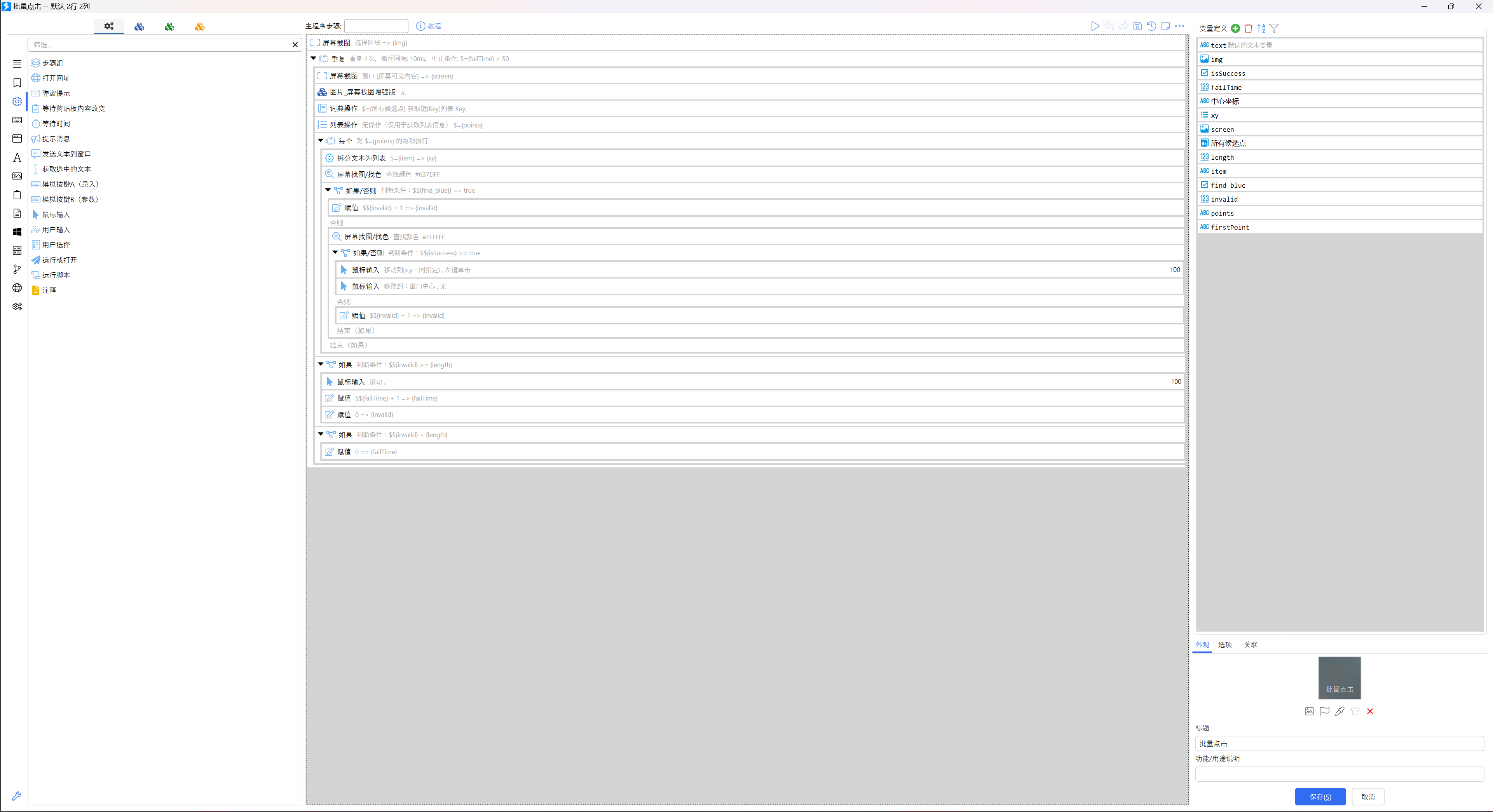
其实明明是很简单的逻辑,但莫名其妙就是很多 bug,,,
但是——但是又来了。这个方法需要占用我的前台鼠标,而且速度其实并不是那么的快。(而且从各种意义上都让我感到很憋屈)
于是我想着能不能用 Power Automate 那种类似于直接 SendMessage 的模拟点击来处理,于是我尝试了一下 Power Automate.
发现它死活找不到对应的 checkbox. 即便用 Recorder 重放也找不到。
然后我又去即兴求助了其他的 RPA 工具,比如 UiPath,下载下来一波操作,成功跑出了一个选中 30 个文件后就会 crash 的绝望版 demo,而且我毫无修复的头绪。
继续执着于 GUI Automation 的我又去看了 pywinauto 这个库,uia backend,看起来很酷,用起来困难重重,反正我失败了(
纠结了一下要不要现场学一个 AutoHotKey,还是算了。
把小白羊源码拉下来准备表演一个现学现卖的二次开发,结果光是拉下来之后 yarn run dev 直接 build 不过,瞬间浇灭了我的幻想(
但此时,我在小白羊的源码文件夹下发现了一团 API 文档。看起来这就是最后的无路可走的唯一之路了——to reinvent the wheel yourself.

Approach Three AliPCS-Py 二开
那么既然决定不用现成的去重,而是自己手搓一个的话,还是用上我熟悉的 Python,上网找一个 API 库。
于是我找到了 https://github.com/PeterDing/AliPCS-Py,当然现在看 aligo 似乎才是那个更好的选择……不过晚了,写都写完了。
AliPCS-Py 虽然用了 Poetry,但我在全新 virtualenv 中跑 poetry install 还是报缺依赖,感觉挺神奇的。把 peewee 和 toml 添加到依赖里就好了。
然后就是蛋疼的开发时间。
一开始写了一个无脑版本,慢得令人叹息。
由于提供的 API 是 requests 的同步版本,那么为了保证效率,就得使用魔法力(
到现在我稍微比较熟悉的也只有 async/await 那一套,用 multi-threading 真的是赶鸭子上架,痛苦万分啊。
在经过与多线程的各种问题搏斗、与输出格式搏斗等等环节之后,经过了艰难的开发:

终于整完力!
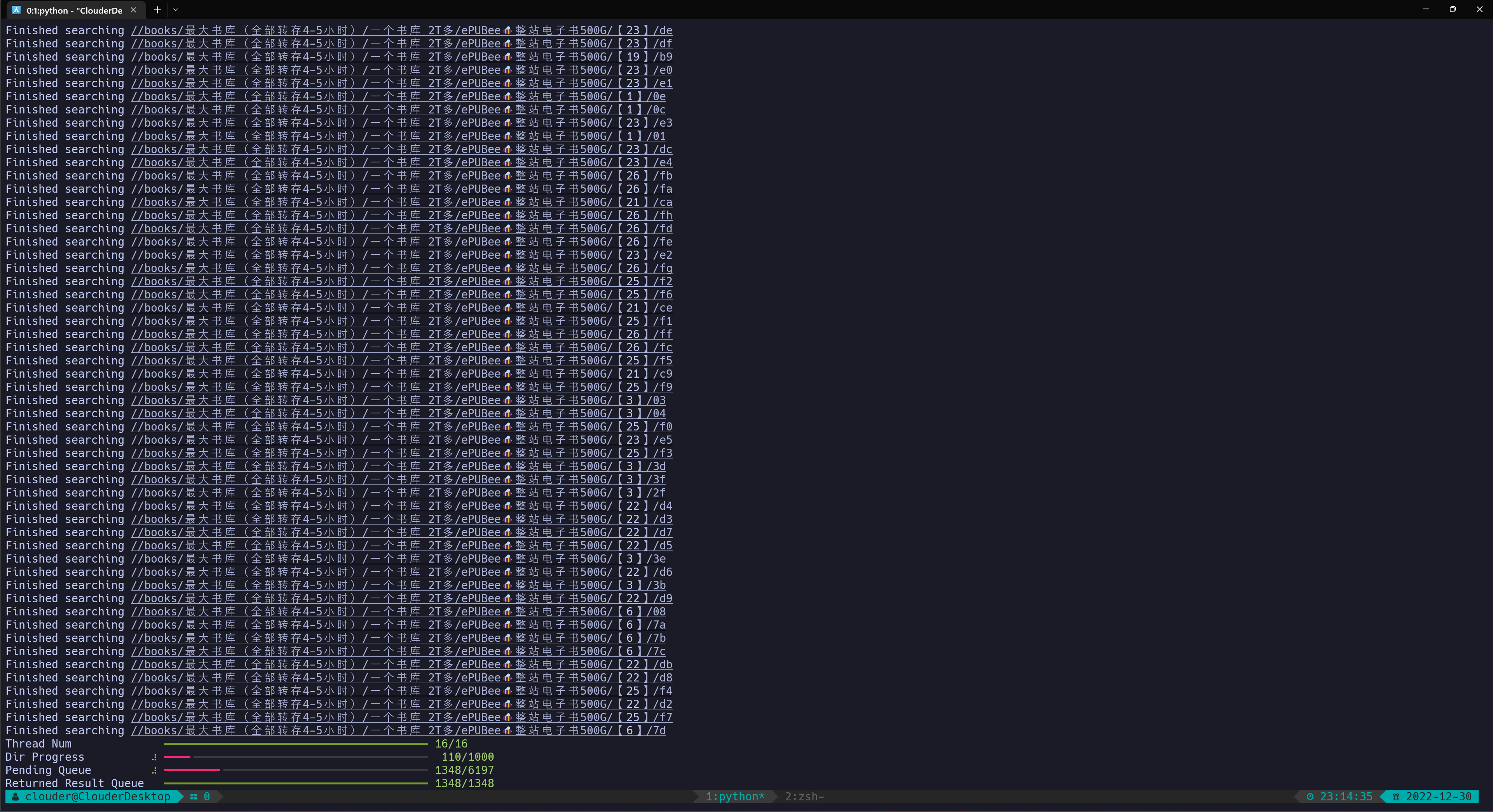
虽然我想的是 Producer/Consumer,但 Consumer 还要把 output 传回去生产新的 input,总之写得乱七八糟,云里雾里,完美诠释了一个一无所知的小萌新试图莫名其妙地达成其目的的凌乱景象。
跑到最后结束阶段更是蛋疼,为了让它们正常地结束我又加了一条监控线程、、、
其实稍微加一些限制就能变成比较优雅的 Producer Consumer 模型,不过稍微损失一点速度。IO heavy 的话其实也是没问题的吧,的吧,的吧……
(毕竟写代码浪费的时间更多啊)
到了删除阶段就清爽多了,是纯真的 batch operation. 对着官方 Document 照葫芦画瓢摸了一段。

然后就差不多啦!
去上游开了一个 Pull Request. 等被 Merge 后各位有需要的就可以使用了(
后记
为什么您们的设计都这么反人类啊!我只是想去个重啊!这是什么刁钻的需求吗!